Este es mi repositorio final de las prácticas de Periodismo de Datos.
Repositorio final de TERESA LÓPEZ en el que se recogen todas las prácticas del curso y los enlaces a las mismas, así como el proceso de creación del repositorio final y de la web junto con el proceso de aprendizaje del curso.
La práctica 1 consta de dos partes:
Este trabajo consiste en el comentario de un trabajo de periodismo de datos. Su fuente es Tresca y expone los datos de una investigación acerca de las Redes Sociales.
Este trabajo consiste en el comentario de un trabajo periodismo de datos a elección del alumno. He escogido una pieza de Newtral con los datos sobre los resultados de las elecciones de Castilla y León del pasado 13 de febrero (13-F).
En esta práctica me sirvo de diferentes trabajos de periodismo de datos para la elaboración de una historia propia. El tema escogido es el Cambio Climático y la fuentes utilizadas la Unión Europea, Red Eléctrica de España y El País. Como en anteriores prácticas, utilizo el lenguaje de marcas estructurado y añado dos fotografías: una infografía de Pinterest y un gráfico del informe de Red Eléctrica que me ayudan a contar la historia.
Este trabajo arranca de los cuadernos con los que hemos trabajado en Jupyter con Python para completarlos comentando qué he hecho, qué entiendo que he hecho y qué me falta por entender. Los cuadernos comprenden los primeros pasos con Python y la reproducción de gráficos a partir de la instalación e importación de librerías (como Pandas, Folium, NumPy o Matplolib), definición de variable, creación del dataframe que exploramos con distintas funciones y definición de las etiquetas para la reproducción gráfica final y visualización de los datos. Los documentos que la componen son los siguientes:
Este es el documento .md explicativo de los cuadernos que componen la práctica. Cada uno puede encontrarse en formato html y ipnyb.
En este cuaderno clasificamos por categorías una serie de datos de la Api de los accidentes de tráfico en la ciudad de Zaragoza registrados por su Ayuntamiento. Además representamos su lugar geográfico en un mapa. Utilizamos la librería Pandas para la reproducción gráfica de los datos y la librería Folium para su visualización en el mapa.
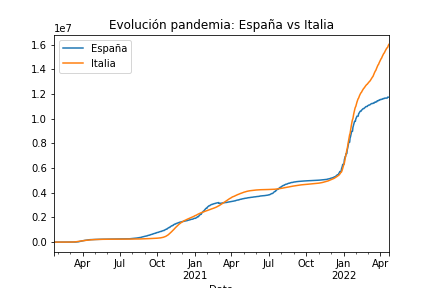
A través de este ejercicio representamos datos de la Api del Covid con la librería Pandas en Python. Tras instalar e importar la librería definimos la variable y creamos el dataframe para, a partir de su exploración, representar la evolución de la pandemia en el tiempo en España, Italia y Francia. Comparamos los escenarios: primero España e Italia y a continuación los tres. Finalmente guardamos los archivos: los datos (.csv) y el gráfico que representa los mismos (.png) de los casos en España e Italia.
Esta práctica consiste en la elaboración de un cuaderno en Jupyter con Python a partir de una base de datos escogida en formato CSV para el análisis, presentación y visualización de los mismos con el objetivo de contar una historia. He escogido un conjunto de datos sobre las tasas e incidencia de la pandemia desde su origen hasta el pasado 29 de marzo en las personas de 60 o más años de edad en el municipio de Alcobendas. Las librerías utilizadas son Pandas y Folium para la representación gráfica de los datos y la visualización de un mapa con marcadores. Todo el proceso queda documentado a través del lenguaje markdown. Finalmente se guardan los datos, un gráfico y mapa resultante que pueden encontrarse en este repositorio.
Este documento .md recoge el proceso de creación de este repositiorio y de la creación de la estructura web que posibilita este trabajo final.
Este documento .md recoge el proceso de aprendizaje a lo largo del curso.
{kind=link}
{kind=link}
{kind=link}
{kind=link}